Los pasados 15 y 16 de noviembre se celebró la edición 2023 de Microsoft Ignite, el evento gratuito online que agrupa presentaciones, sesiones de trabajo y debates con expertos en torno a las incorporaciones y novedades en materia de tecnología e inteligencia artificial.
Una de las sesiones más relevantes fue la relativa al funcionamiento de Copilot para Microsoft 365, que en poco más de 45 minutos permitió desvelar, a la vez que desmitificar, las entrañas del modelo de lenguaje basado en OpenAI para el entorno de aplicativos de oficina de la suite empresarial. Hemos querido tomar nota en esta página de la sesión realizada por David Conger, Principal Product Manager en el equipo de la oficina de IA de Microsoft, que en apenas 6 minutos enseñó «las tripas» de la maquinaria y qué es lo que hace posible su funcionamiento. Mostramos a continuación la transcripción completa de este fragmento del evento, acompañada de las diapositivas que Conger utilizó en su breve pero intensa intervención.
«Una de las preguntas más importantes que recibo cuando la gente ve esto es: ¿cómo Copilot realmente controla la aplicación? Vamos a desmitificar eso un poco en cómo logramos esto entre bastidores. Hay algunas cosas que necesitamos. Primero, necesitamos el estado actual del documento en sí o de la aplicación con la que estamos trabajando. Necesitamos el contenido que, por supuesto, se va a generar y crear con Copilot, y necesitamos un flujo de ejecución seguro. Sé que esto es importante para muchos de ustedes en cómo interactuamos realmente con la aplicación para producir ese contenido final y crear ese contenido en la aplicación.
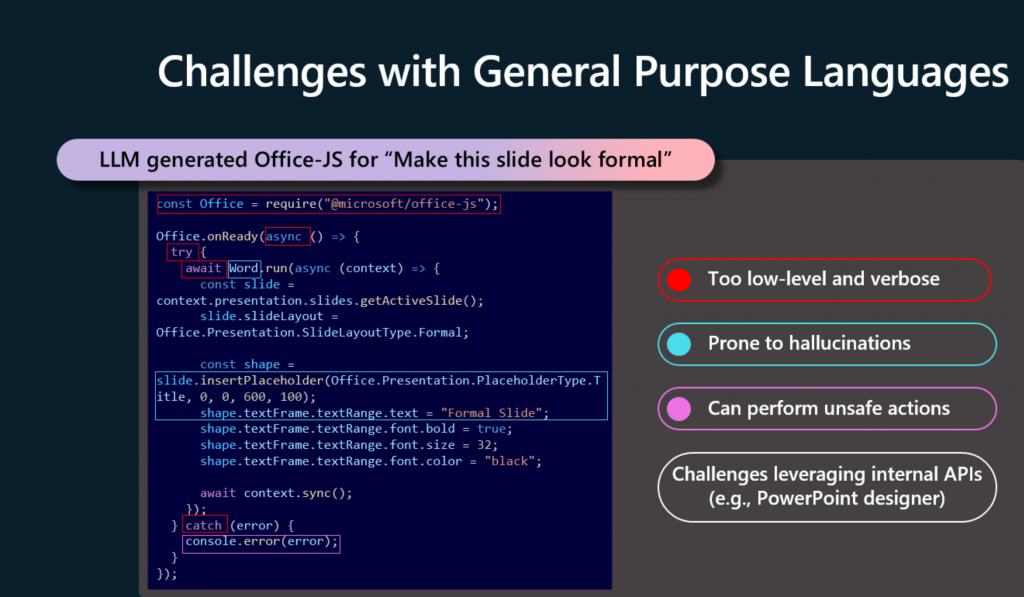
»Ahora, cuando comenzamos a hablar de esto, mucha gente salta inmediatamente a la idea de que probablemente la forma en que hacemos esto es mediante el uso de un lenguaje de propósito general como Office-JS y pidiendo al LLM que nos cree código en ese lenguaje. Pero esto presenta una serie de problemas. Primero, el lenguaje es demasiado detallado. Es muy verboso en lo que crea, y es difícil para nosotros manipularlo y validar lo que crea. En segundo lugar, sabemos que los LLM son propensos a la alucinación, y esto se convierte en un problema cuando el código parece correcto, pero rápidamente se encuentra que está equivocado. Abre mucha superficie. Office-JS y otros lenguajes nativos son realmente potentes y hay algunas cosas que no queremos que el LLM haga dentro de la aplicación en este momento.
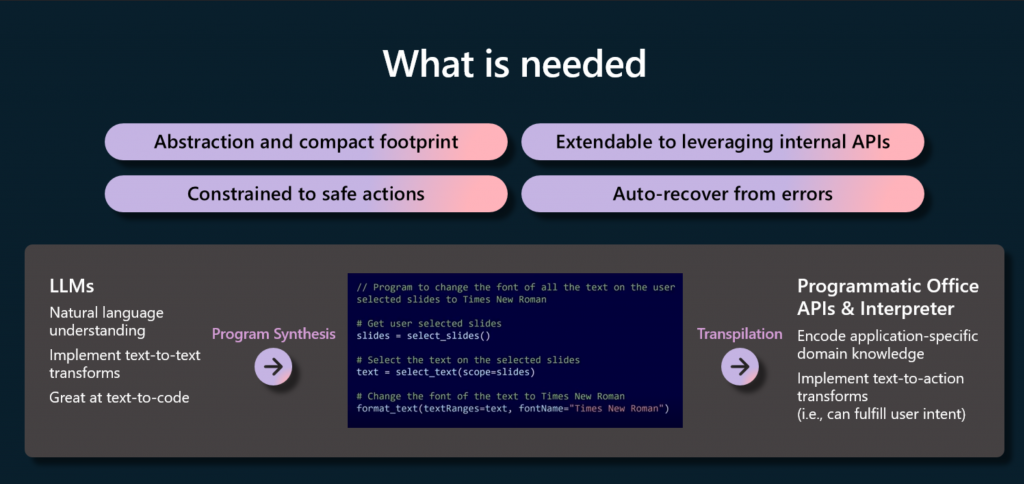
»Con eso, lo que realmente encontramos que necesitamos es separar las preocupaciones. El LLM en sí mismo es muy bueno para entender la intención, es bueno para resolver ciertos tipos de problemas, y nuestras API son muy buenas para ejecutarse dentro de la aplicación. ¿Cómo hacemos esto? Bueno, aprovechamos referencias simbólicas a entidades. Necesitamos asegurarnos de que esas estén incluidas en lo que estamos creando. También necesitamos asegurarnos de no perder de vista la capacidad de crear flujos complejos. Sabemos que un desarrollador humano podría hacer esto dentro de un lenguaje nativo, y necesitamos que el LLM pueda hacer esto de nuevo de una manera segura.
»Finalmente, sí necesitamos poder detectar y recuperarnos. Dado que no tenemos un grupo activo de desarrolladores desarrollando esto, necesitamos encontrar problemas y solucionarlos antes de ejecutar el código. La síntesis de programas es el método que usamos para hacer esto. El LLM se abstrae del código en sí mismo y luego usamos la transpilación para terminar generando el código y ejecutándolo en el cliente. Para nosotros, hemos creado un DSL, un lenguaje específico del dominio, que llamamos ODSL, o el lenguaje específico del dominio de Office para hacer esto.

»Construimos dinámicamente indicaciones y traducimos la intención del usuario natural en un programa DSL. Es fácilmente autorizado por el LLM, es muy claro cómo puede crear esto, y luego podemos generar un código consistente a partir de ese DSL para ser ejecutado. Permítanme caminar brevemente a través de los principales componentes que ven aquí para que puedan entender mejor los flujos de datos y cómo ocurre la ejecución y cómo mantenemos las cosas seguras.
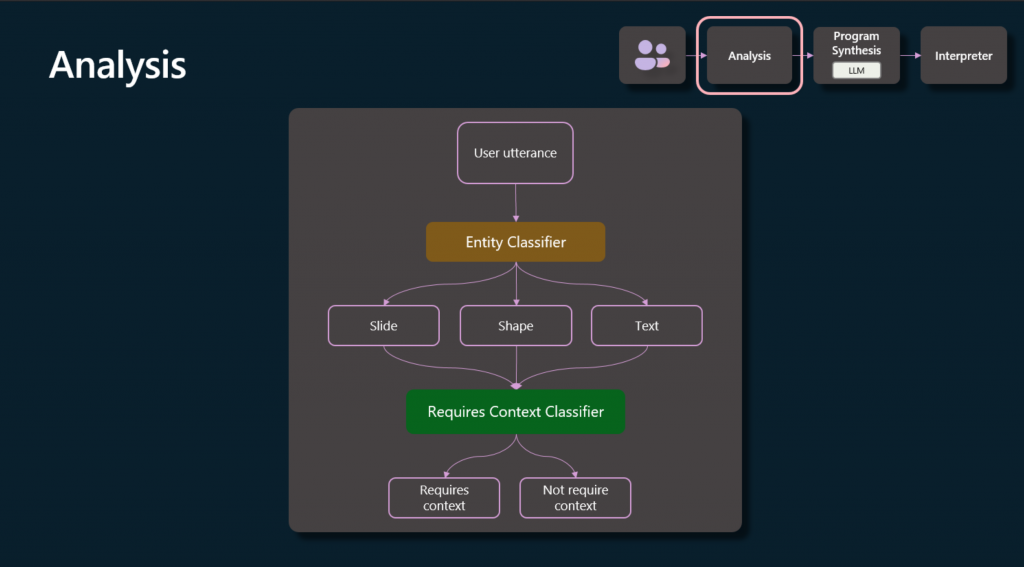
»Primero, hacemos una clasificación de entidades. Queremos entender qué tipos de entidades vamos a necesitar interactuar, ya sea para realizar cambios o para generar el contenido en sí mismo, y queremos determinar cuán relevante es el contexto del documento en sí. Vimos eso en algunos de los ejemplos anteriores. La diapositiva que creé, por ejemplo, no requería ningún contexto del documento, pero la manipulación posterior de una diapositiva que ya tenía, sí lo hacía.
»A medida que avanzamos hacia la construcción y síntesis, hay algunas cosas que deben tener en cuenta, que es básicamente un proceso de cinco pasos para preparar la indicación para el LLM. La primera son las reglas en sí mismas que el LLM necesita seguir. La segunda es esa guía de sintaxis para ODSL, porque, por supuesto, necesitamos enseñarle qué puede y no puede generar.
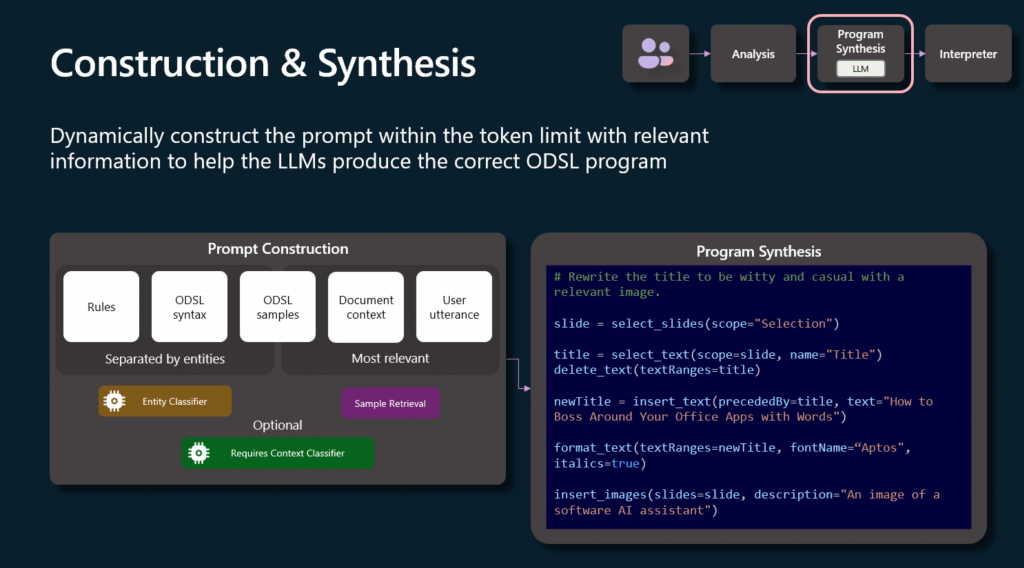
»Ahora, queremos mantener la indicación tan afinada como sea posible, así que tenemos una gran biblioteca de indicaciones potenciales de tipos de DSL que podrían generarse. Usamos eso con el paso anterior, el análisis que hicimos para encontrar ejemplos de código que podrían ser más relevantes para el LLM. Esto nos permite mantener ese paquete muy pequeño que enviamos y orientado a la propia indicación solo a los tipos de acciones que creemos que son más propensas a ser necesarias por el LLM. Por supuesto, también incluimos el contexto del documento y la consulta del usuario en sí.
»A la derecha, pueden ver esa síntesis de programas que se está generando. Notarán algunas cosas dentro de ella. Primero, hay un nivel de uniformidad en el código. Declaraciones similares, es fácil de leer, fue más fácil para el LLM producirlo. Pueden ver estos patrones si observan a través de las diferentes aplicaciones que se están generando también para ver que es un concepto muy similar en todas las aplicaciones.
»En segundo lugar, la sintaxis es muy compacta. Está sucediendo bastante aquí en un corto período de tiempo; realmente hemos optimizado en ambos extremos para los tokens y tokens de salida para tratar de limitar la cantidad que necesitamos utilizar dentro del sistema. Finalmente, estamos muy conscientes del contexto del documento, como pueden ver los campos y propiedades y datos que se manipulan en la síntesis de programas aquí.

»En el último paso interpretamos y ejecutamos. Aquí es donde transpilamos a API nativas como Office-JS y ejecutamos en el cliente mismo. Controlamos las declaraciones permitidas en este flujo, por lo que solo permitimos ciertos tipos de código generados a partir del DSL, protegiéndonos de acciones como la escritura de archivos, que no necesitamos hacer.
También tenemos una comprobación y validación rigurosas de sintaxis para asegurarnos de que el programa sea correcto antes de intentar ejecutarlo, e incluso podemos corregir código con errores debido a cómo funciona el DSL y cómo se manipula el DSL, podemos asegurarnos de que las correcciones se puedan hacer sobre la marcha nuevamente antes de ejecutar. Muy rápidamente, el DSL se genera y se ejecuta en el cliente, y en este punto tenemos un programa robusto, seguro y verificado para completar la tarea.»
Una intervención llena de significados para tener una dimensión completa de las implicaciones y alcance que supone contar con motores de IA dentro de nuestra actividad diaria. Como muy bien afirma el CTO de nuestra firma gemela, Eflow, Daniel Hermosel: «abre puertas a cosas nuevas que te van abriendo más puertas y no acabas nunca». Con toda la ironía del mundo remacha con «esto es lo malo». Aunque él, y nosotros, y todos los lectores de este blog puedan entender que esa ironía significa exactamente lo contrario: «esto es lo bueno». Es tan bueno que cuesta asimilarlo de una sola vez.
Imágenes Microsoft Ignite
Foto de portada Dima Pechurin en Unsplash